Crawlab是一款基于 Golang 的分布式爬虫管理平台,支持 Python、NodeJS、Go、Java、PHP 等多种编程语言以及多种爬虫框架。
1谁适合使用 Crawlab?
-
网路爬虫工程师: 通过集成爬虫程序到 Crawlab,网路爬虫工程师可以聚焦于爬虫的核心解析逻辑,从而避免浪费过多时间在开发通用模块上,例如任务队列、存储、日志、消息通知等。 -
运维工程师: Crawlab 对于运维工程师来说最大的好处是部署便利(对于爬虫程序和 Crawlab 本身)。Crawlab 支持 Docker 或 Kubernetes 一键安装。 -
数据分析师: 数据分析师如果能写代码(例如 Python),则可以开发爬虫程序(例如 Scrapy)然后上传到 Crawlab,然后就可以把所有脏活累活交给 Crawlab,它能够自动抓取数据。 -
其他: 准确的说,任何人都能够享受 Crawlab 自动化带来的便利。虽然 Crawlab 尤其擅长执行网络爬虫任务,但它不仅限于此,它能够被用来运行其他类型的任务,例如数据处理和自动化。
2快速开始
请打开命令行并执行下列命令。请保证已经提前安装了 docker-compose。
git clone https://github.com/crawlab-team/examples
cd examples/docker/basic
docker-compose up -d
接下来,可以看 docker-compose.yml (包含详细配置参数),以及参考 文档 来查看更多信息。
文档:https://docs.crawlab.cn/zh/guide/
3运行
Docker
请用docker-compose来一键启动,甚至不用配置 MongoDB 数据库,「当然我们推荐这样做」。在当前目录中创建docker-compose.yml文件,输入以下内容。
version: '3.3'
services:
master:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_master
environment:
CRAWLAB_NODE_MASTER: "Y"
CRAWLAB_MONGO_HOST: "mongo"
volumes:
- "./.crawlab/master:/root/.crawlab"
ports:
- "8080:8080"
depends_on:
- mongo
worker01:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker01
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker01:/root/.crawlab"
depends_on:
- master
worker02:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker02
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker02:/root/.crawlab"
depends_on:
- master
mongo:
image: mongo:4.2
container_name: crawlab_example_mongo
restart: always
然后执行以下命令,Crawlab 主节点、工作节点+ MongoDB 就启动了。打开http://localhost:8080就能看到界面。
docker-compose up -d
Docker 部署的详情,请见相关文档。
文档:https://docs.crawlab.cn/zh/guide/installation/docker.html
4截图
登陆页

主页
节点列表
爬虫列表
爬虫概览
爬虫文件
任务日志
任务结果
定时任务
5架构
Crawlab 的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及 SeaweedFS (分布式文件系统) 和 MongoDB 数据库。
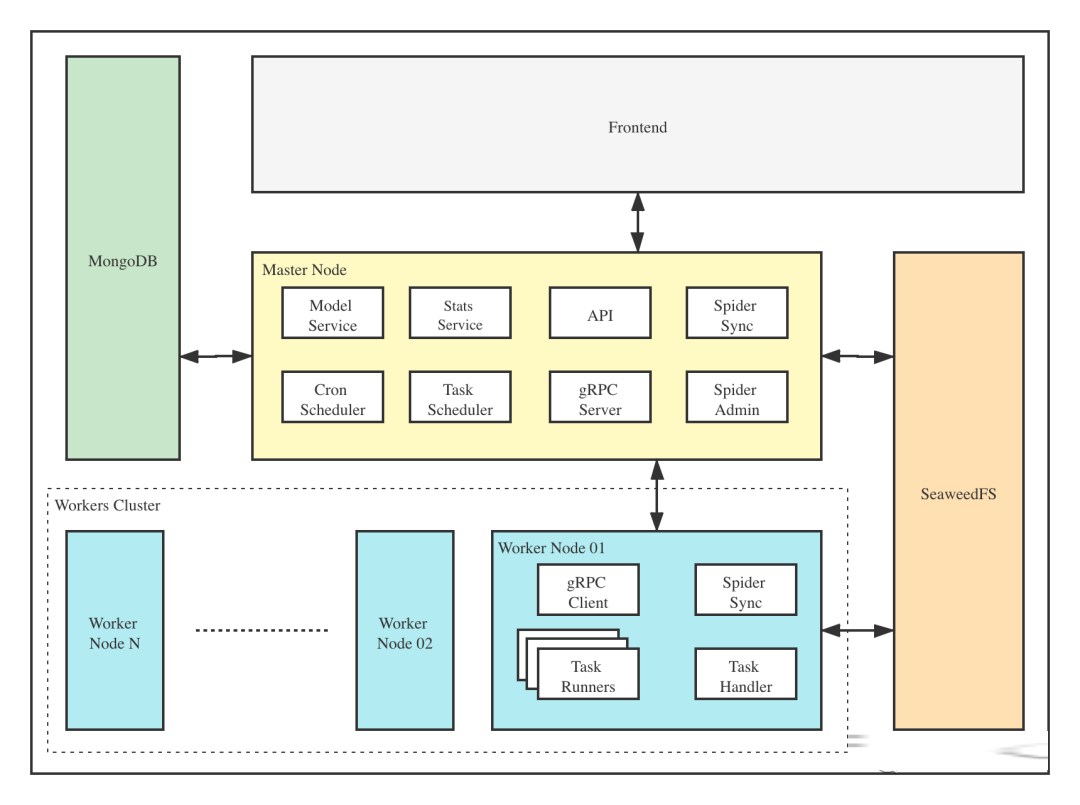
前端应用与主节点 (Master Node) 进行交互,主节点与其他模块(例如 MongoDB、SeaweedFS、工作节点)进行通信。主节点和工作节点 (Worker Nodes) 通过 gRPC (一种 RPC 框架) 进行通信。
任务通过主节点上的任务调度器 (Task Scheduler) 进行调度分发,并被工作节点上的任务处理模块 (Task Handler) 接收,然后分配到任务执行器 (Task Runners) 中。任务执行器实际上是执行爬虫程序的进程,它可以通过 gRPC (内置于 SDK) 发送数据到其他数据源中,例如 MongoDB。
主节点
主节点是整个 Crawlab 架构的核心,属于 Crawlab 的中控系统。
主节点主要负责以下功能:
-
爬虫任务调度 -
工作节点管理和通信 -
爬虫部署 -
前端以及 API 服务 -
执行任务(可以将主节点当成工作节点)
主节点负责与前端应用进行通信,并将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫到分布式文件系统 SeaweedFS,用于工作节点的文件同步。
工作节点
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过 Redis 的PubSub跟主节点通信。通过增加工作节点数量,Crawlab 可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。
MongoDB
MongoDB 是 Crawlab 的运行数据库,储存有节点、爬虫、任务、定时任务等数据。任务队列也储存在 MongoDB 里。
SeaweedFS
SeaweedFS 是分布式文件系统,由 Chris Lu 开发和维护。它能在分布式系统中有效稳定的储存和共享文件。在 Crawlab 中,SeaweedFS 主要用作文件同步和日志存储。
前端
前端应用是基于 Element-Plus 构建的,它是基于 Vue 3 的 UI 框架。前端应用与主节点上的 API 进行交互,并间接控制工作节点。
6与其他框架的集成
Crawlab SDK 提供了一些 helper 方法来让爬虫更好的集成到 Crawlab 中,例如保存结果数据到 Crawlab 中等等。
集成 Scrapy
在 settings.py 中找到 ITEM_PIPELINES(dict 类型的变量),在其中添加如下内容。
ITEM_PIPELINES = {
'crawlab.scrapy.pipelines.CrawlabPipeline': 888,
}
然后,启动 Scrapy 爬虫,运行完成之后,就应该能看到抓取结果出现在 「任务详情 -> 数据」 里。
通用 Python 爬虫
将下列代码加入到爬虫中的结果保存部分。
# 引入保存结果方法
from crawlab import save_item
# 这是一个结果,需要为 dict 类型
result = {'name': 'crawlab'}
# 调用保存结果方法
save_item(result)
然后,启动爬虫,运行完成之后,就应该能看到抓取结果出现在 「任务详情 -> 数据」 里。
其他框架和语言
爬虫任务实际上是通过 shell 命令执行的。任务 ID (Task ID) 作为环境变量 CRAWLAB_TASK_ID 被传入爬虫任务进程中,从而抓取的数据可以跟任务管理。
7与其他框架比较
现在已经有一些爬虫管理框架了,因此为啥还要用 Crawlab?
因为很多现有当平台都依赖于 Scrapyd,限制了爬虫的编程语言以及框架,爬虫工程师只能用 scrapy 和 python。当然,scrapy 是非常优秀的爬虫框架,但是它不能做一切事情。
Crawlab 使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
评论(0)