今天给大家介绍一款 Python 爬虫项目,支持小红书爬虫,抖音爬虫, 快手爬虫, B站爬虫, 微博爬虫…。
❝目前能抓取小红书、抖音、快手、B站、微博的视频、图片、评论、点赞、转发等信息。
❞
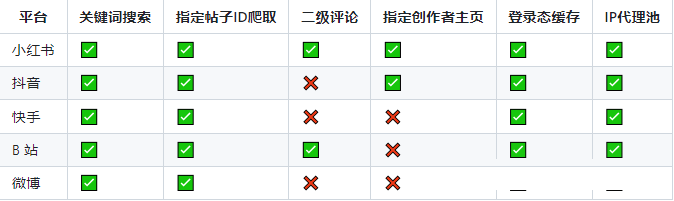
功能列表
下面不支持的项目,相关的代码架构已经搭建好,只需要实现对应的方法即可
使用方法
创建并激活 python 虚拟环境
# 进入项目根目录
cd MediaCrawler
# 创建虚拟环境
# 注意python 版本需要3.7 - 3.9
python -m venv venv
# macos & linux 激活虚拟环境
source venv/bin/activate
# windows 激活虚拟环境
venv\Scripts\activate
安装依赖库
pip3 install -r requirements.txt
安装 playwright浏览器驱动
playwright install
运行爬虫程序
### 项目默认是没有开启评论爬取模式,如需评论请在config/base_config.py中的 ENABLE_GET_COMMENTS 变量修改
### 一些其他支持项,也可以在config/base_config.py查看功能,写的有中文注释
# 从配置文件中读取关键词搜索相关的帖子并爬取帖子信息与评论
python main.py --platform xhs --lt qrcode --type search
# 从配置文件中读取指定的帖子ID列表获取指定帖子的信息与评论信息
python main.py --platform xhs --lt qrcode --type detail
# 打开对应APP扫二维码登录
# 其他平台爬虫使用示例,执行下面的命令查看
python main.py --help
数据保存
-
支持保存到关系型数据库(Mysql、PgSQL等) -
执行 python db.py 初始化数据库数据库表结构(只在首次执行)
-
-
支持保存到csv中(data/目录下) -
支持保存到json中(data/目录下)
版权声明:
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
评论(0)