近年来,随着大语言模型(LLM)技术的突破,文本生成领域迎来了爆发式发展。然而,如何让AI“开口说话”并赋予其自然的情感表达,仍是技术探索的前沿方向。
由社区驱动的项目 Fish-Speech 在这一领域交出了一份亮眼的答卷。它不仅实现了高质量的零样本语音克隆(Zero-shot TTS),更通过创新的 Fish Agent 架构,将语音合成与对话能力深度融合,为开发者提供了开箱即用的多语言语音交互解决方案。
简介
Fish-Speech仅需 10-30秒的参考音频 即可生成高度拟真的语音,而且支持8种语言自由切换。这是一款语音合成新标杆,在GitHub上拥有19.4k star。
核心功能
1. 零样本语音克隆:打破传统TTS限制
传统语音合成(TTS)需要大量目标音色的训练数据,而Fish-Speech仅需 10-30秒的参考音频 即可生成高度拟真的语音。其核心技术通过对比学习与声学特征解耦,实现音色与发音风格的精准分离,用户无需标注数据即可完成个性化语音定制。
2. 多语言混合输入的“无国界”支持
项目原生支持 中、英、日、韩、法、德、阿拉伯、西班牙 等8种语言的混合文本输入,无需依赖音素标注或语言切换操作。例如,用户可直接输入“Hello,今天天气不错,一緒に散歩しませんか?”这类跨语言文本,模型将自动识别并生成连贯语音。
3. 高准确率与极速推理
在Nvidia RTX 4060显卡上,Fish-Speech的实时推理速度可达 1:5(音频时长:处理时长),且英语长文本的字符错误率(CER)低至 2%。这得益于其优化的声学模型架构与自研的推理加速技术(fish-tech),显著降低了硬件门槛。
4. Fish Agent:端到端的语音交互革命
区别于传统“ASR→LLM→TTS”的三段式流程,Fish Agent实现了 完全端到端的语音对话:
-
情感控制: 通过参考音频调节输出语音的情感强度(如兴奋、悲伤)。 -
音色一致性: 在长对话中保持音色稳定,避免传统TTS的“机械感”。 -
多模态理解: 直接处理语音输入并生成带情感的语音回复,无需中间文本转换。
快速上手
环境部署
git clone https://github.com/fishaudio/fish-speech
cd fish-speech && pip install -r requirements.txt
启动WebUI
通过Gradio界面一键体验语音克隆与多语言合成:
python scripts/webui.py --device cuda
API服务化
支持Docker快速部署高并发推理服务:
docker build -t fish-speech .
docker run -p 8000:8000 fish-speech
展示
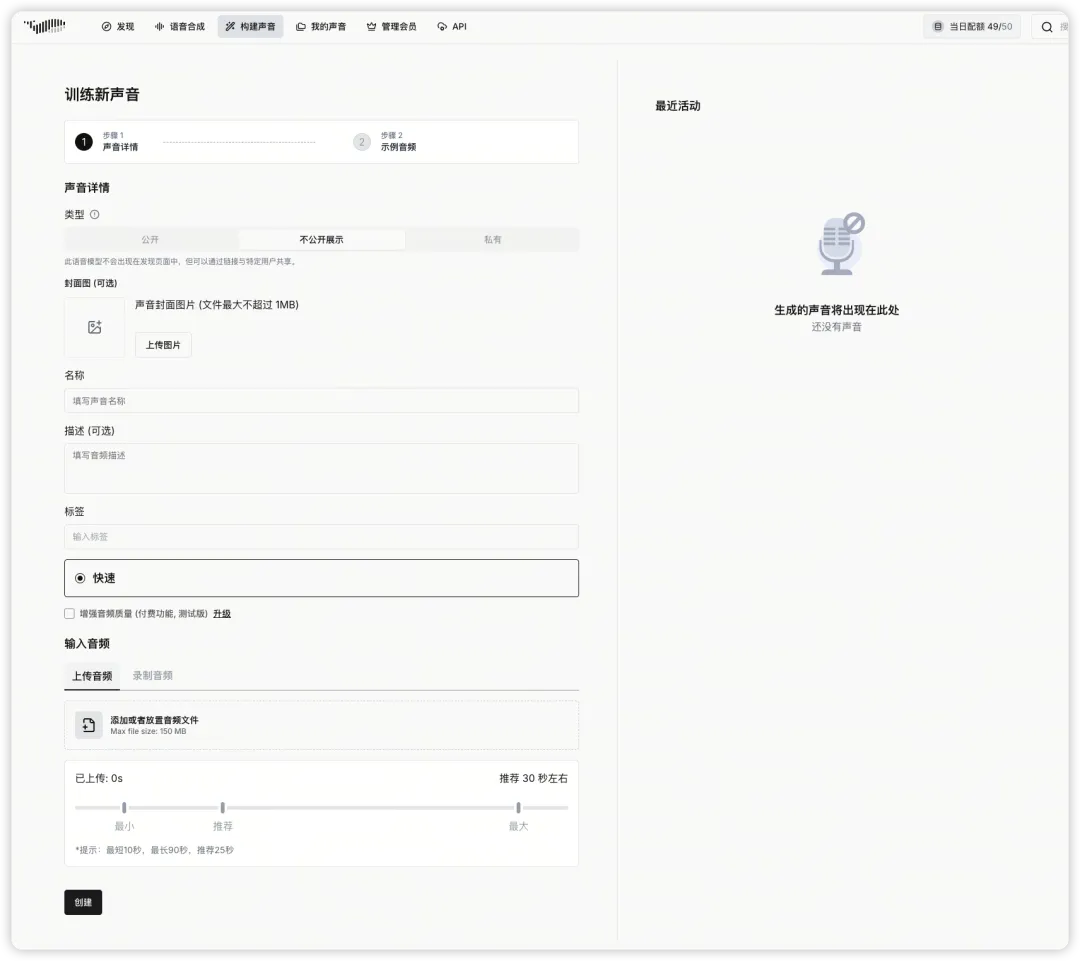
录入声音,方便后续克隆使用:
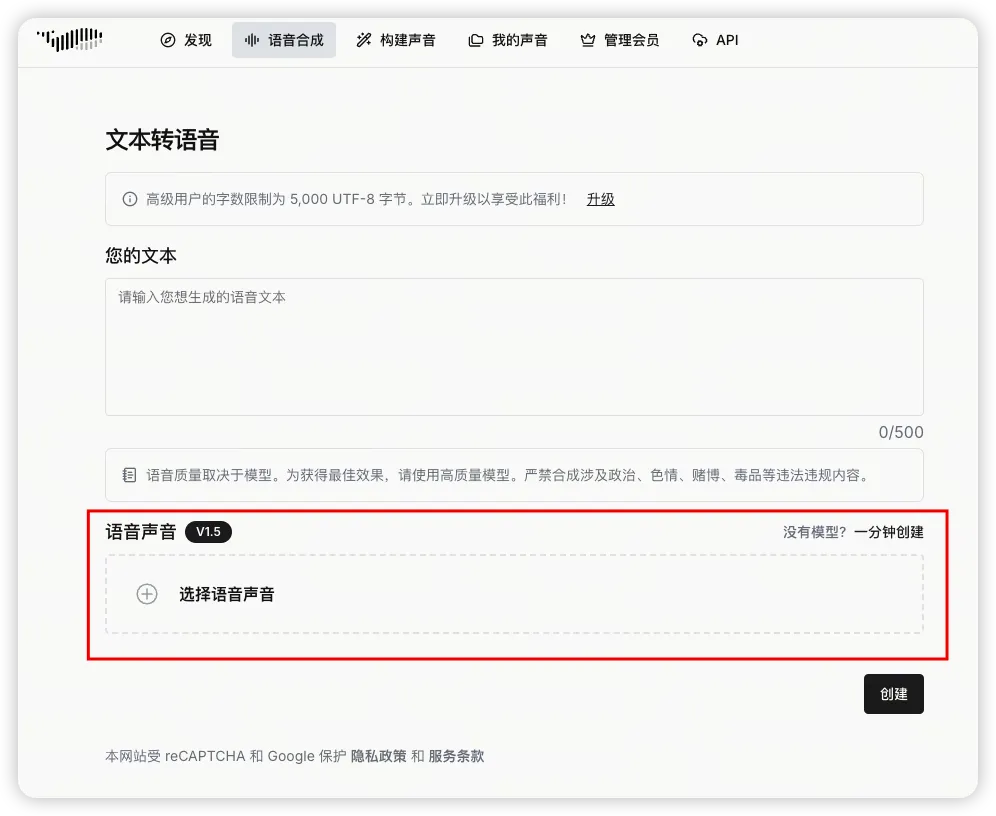
输入你想要说的文本内容,选择你想要克隆的声音:
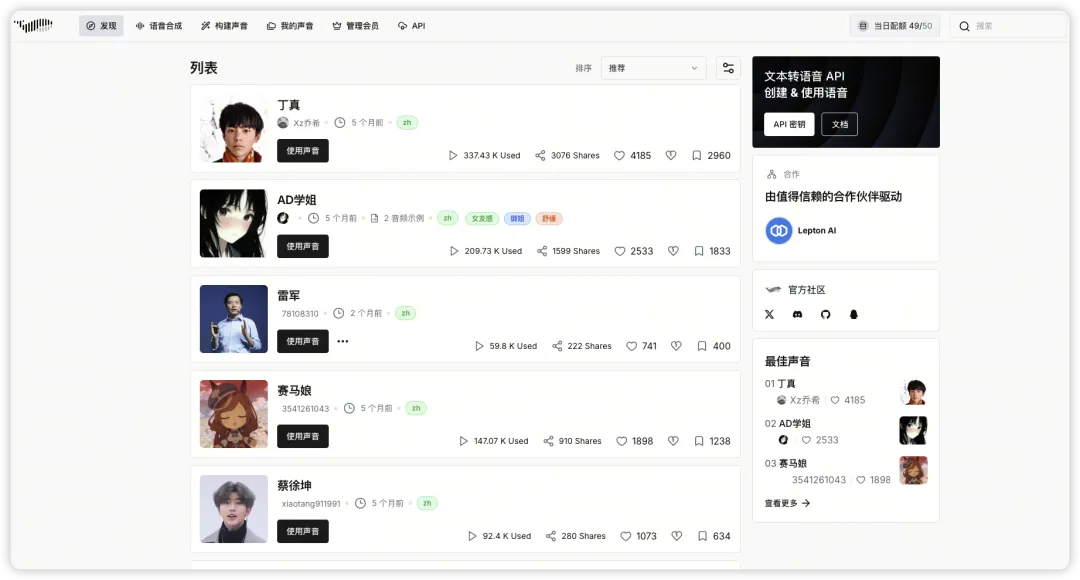
除了自己的声音可用,还有大量的声音示例可用
总结
Fish-Speech的诞生,标志社区在语音合成领域已具备与商业产品竞争的技术实力。其零样本学习、端到端对话与多语言支持的特性,为AI语音应用开辟了新的可能性。无论是开发者、研究者还是技术爱好者,均可通过这一项目探索语音技术的未来边界。
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
评论(0)