今天,百度正式文心大模型 4.5。这是百度继文心大模型系列持续演进后的又一关键里程碑,也是国产通用大模型走向更开放、更实用的重要信号。
模力方舟作为首批合作平台之一,在开源首日即完成文心大模型4.5的全量接入与上线。即日起,用户可在模力方舟平台上在线体验并下载完整模型权重,自主部署、深度定制,真正实现大模型的可用、好用与可落地。
强大性能,全面开放:文心大模型4.5正式发布
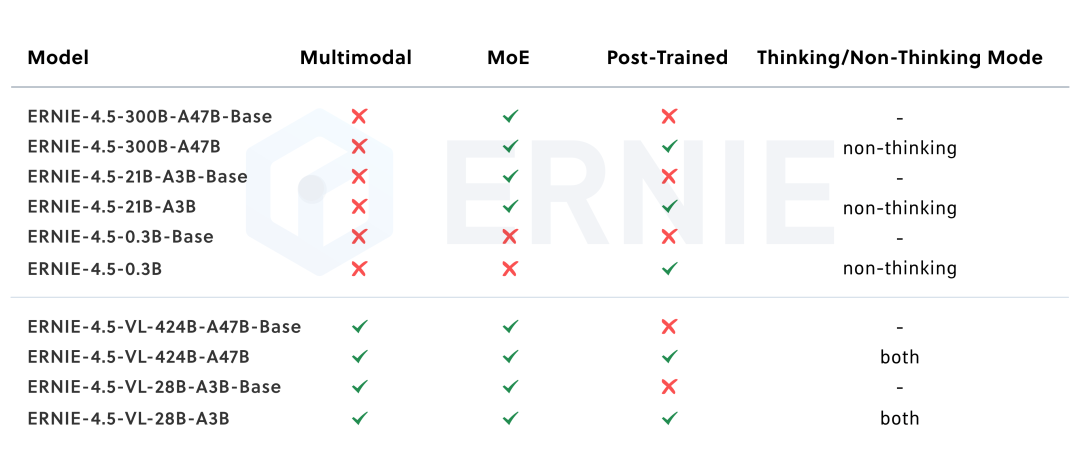
文心4.5系列模型共10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。
针对 MoE 架构,百度提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。此架构非常适用于从大语言模型向多模态模型的持续预训练范式,在保持甚至提升文本任务性能的基础上,显著增强多模态理解能力。
文心4.5系列模型均使用飞桨深度学习框架进行高效训练、推理和部署。在大语言模型的预训练中,模型FLOPs利用率(MFU)达到47%。实验结果显示,该系列模型在多个文本和多模态基准测试中达到SOTA水平,在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果尤为突出。模型权重按照Apache 2.0协议,支持开展学术研究和产业应用。此外,基于飞桨提供的产业级开发套件,广泛兼容多种芯片,降低后训练和部署门槛。
模型技术优势
文心4.5 通过在文本和视觉两种模态上进行联合训练,更好地捕捉多模态信息中的细微差别,提升在文本生成、图像理解以及多模态推理等任务中的表现。为了让两种模态学习时互相提升,百度提出了一种多模态异构混合专家模型结构,结合了多维旋转位置编码,并且在损失函数计算时,增强了不同专家间的正交性,同时对不同模态间的词元进行平衡优化,达到多模态相互促进提升的目的。
为了支持 文心4.5 模型的高效训练,百度提出了异构混合并行和多层级负载均衡策略。通过节点内专家并行、显存友好的流水线调度、FP8混合精度训练和细粒度重计算等多项技术,显著提升了预训练吞吐。推理方面,百度提出了多专家并行协同量化方法和卷积编码量化算法 ,实现了效果接近无损的4-bit 量化和2-bit 量化。此外,百度还实现了动态角色转换的预填充、解码分离部署技术,可以更充分地利用资源,提升文心4.5 MoE 模型的推理性能。基于飞桨框架,文心4.5 在多种硬件平台均表现出优异的推理性能。
为了满足实际场景的不同要求,百度对预训练模型进行了针对模态的精调。其中,大语言模型针对通用语言理解和生成进行了优化,多模态大模型侧重于视觉语言理解,支持思考和非思考模式。每个模型采用了SFT、DPO或UPO(Unified Preference Optimization,统一偏好优化技术)的多阶段后训练。
模力方舟首发上线,打造即用即开的国产模型平台
作为领先的国产人工智能服务平台,模力方舟致力于提供开放、轻量、易用的大模型服务,模力方舟的 AI 模型广场提供了行业大模型、文本生成、视觉模型、语音多模态等十三大类共 109 款各领域的顶尖开源模型的在线体验和 API 使用。通过购买模型资源包,即可通过极低的价格即可尽享众多主流模型。
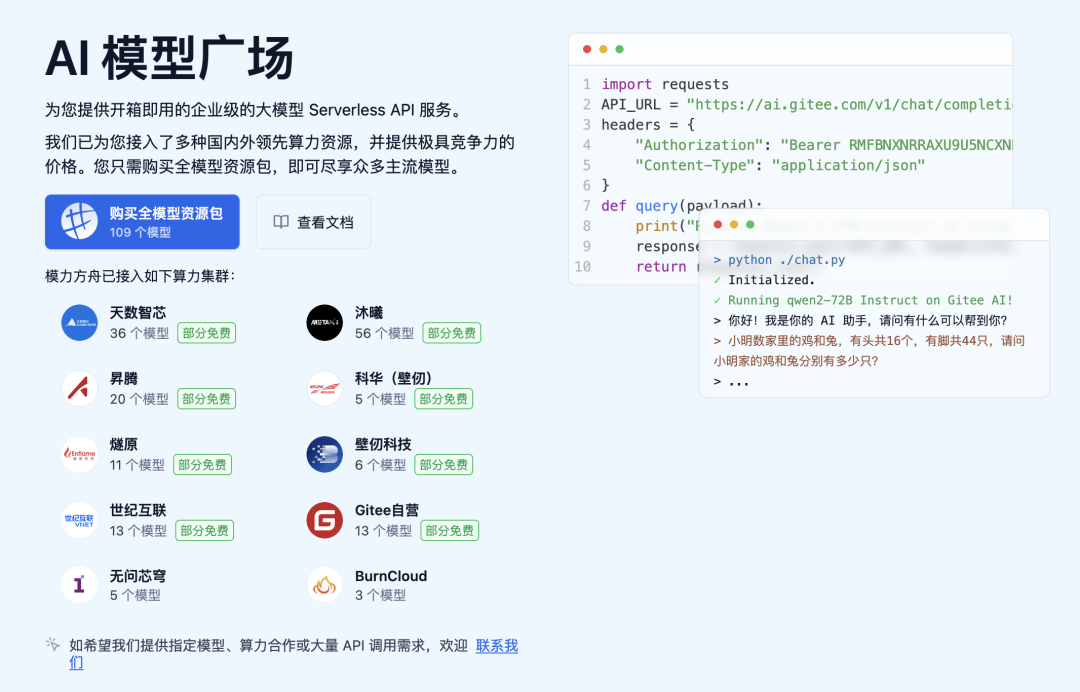
此次文心大模型 4.5 的上线,进一步完善了模力方舟在国产主力模型方向的覆盖能力,也为用户提供了更多具备工程可落地性的模型选项。
为什么选择模力方舟:
-
全托管体验:无需本地部署,模型即开即用; -
灵活调用方式:支持 API 调用与在线交互,便于接入现有业务; -
强大算力支撑:依托国产 GPU 架构,低成本体验大模型推理; -
全面国产生态适配:兼容本地私有化部署、国密标准与信创环境。
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
评论(0)