webmagic 是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
本项目在GitHub上有11.4K Star,非常热门,让不熟悉爬虫的小白也可以玩转爬虫。
申明:此教程仅供爬虫学习交流使用,切忌非法使用爬虫!
主要特色
-
完全模块化的设计,强大的可扩展性。 -
核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。 -
提供丰富的抽取页面API。 -
无配置,但是可通过POJO+注解形式实现一个爬虫。 -
支持多线程。 -
支持分布式。 -
支持爬取js动态渲染的页面。 -
无框架依赖,可以灵活的嵌入到项目中去。
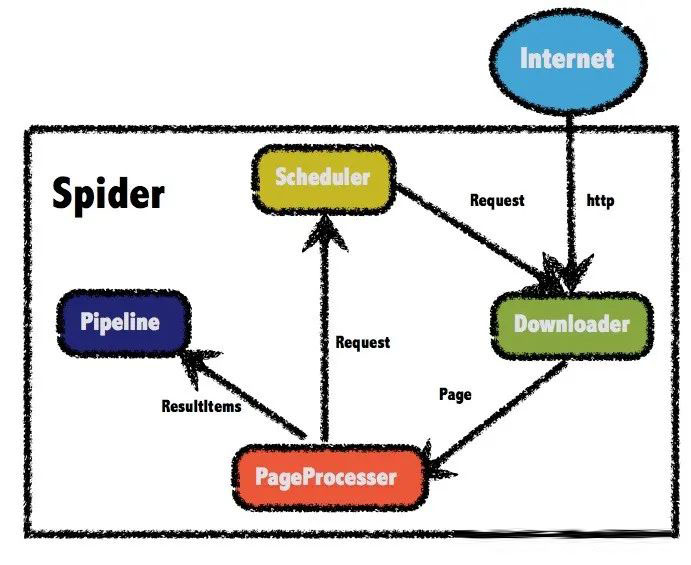
总体架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
快速开始
引入依赖
webmagic使用maven管理依赖,在项目中添加对应的依赖即可使用webmagic:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.5</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.5</version>
</dependency>
WebMagic 使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
第一个爬虫
定制PageProcessor
PageProcessor是webmagic-core的一部分,定制一个PageProcessor即可实现自己的爬虫逻辑。
以下是抓取osc博客的一段代码:
public class OschinaBlogPageProcessor implements PageProcessor {
private Site site = Site.me().setDomain("my.oschina.net");
@Override
public void process(Page page) {
List<String> links = page.getHtml().links().regex("http://my\\.oschina\\.net/flashsword/blog/\\d+").all();
page.addTargetRequests(links);
page.putField("title", page.getHtml().xpath("//div[@class='BlogEntity']/div[@class='BlogTitle']/h1").toString());
page.putField("content", page.getHtml().$("div.content").toString());
page.putField("tags",page.getHtml().xpath("//div[@class='BlogTags']/a/text()").all());
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new OschinaBlogPageProcessor()).addUrl("http://my.oschina.net/flashsword/blog")
.addPipeline(new ConsolePipeline()).run();
}
}
这里通过page.addTargetRequests()方法来增加要抓取的URL,并通过page.putField()来保存抽取结果。page.getHtml().xpath()则是按照某个规则对结果进行抽取,这里抽取支持链式调用。调用结束后,toString()表示转化为单个String,all()则转化为一个String列表。
Spider是爬虫的入口类。Pipeline是结果输出和持久化的接口,这里ConsolePipeline表示结果输出到控制台。
执行这个main方法,即可在控制台看到抓取结果。webmagic默认有3秒抓取间隔,请耐心等待。
使用注解
webmagic-extension包括了注解方式编写爬虫的方法,只需基于一个POJO增加注解即可完成一个爬虫。以下仍然是抓取oschina博客的一段代码,功能与OschinaBlogPageProcesser完全相同:
@TargetUrl("http://my.oschina.net/flashsword/blog/\\d+")
public class OschinaBlog {
@ExtractBy("//title")
private String title;
@ExtractBy(value = "div.BlogContent",type = ExtractBy.Type.Css)
private String content;
@ExtractBy(value = "//div[@class='BlogTags']/a/text()", multi = true)
private List<String> tags;
public static void main(String[] args) {
OOSpider.create(
Site.me(),
new ConsolePageModelPipeline(), OschinaBlog.class).addUrl("http://my.oschina.net/flashsword/blog").run();
}
}
这个例子定义了一个Model类,Model类的字段title、content、tags均为要抽取的属性。这个类在Pipeline里是可以复用的。
1、本网站名称:帝企吧
2、本站永久网址:https://www.diqiba.com
3、本网站的文章部分内容可能来源于网络及作者投稿,仅供大家学习与参考,如有侵权,请联系站长进行删除处理。
4、本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5、本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6、本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
7、本站所有资源来源于互联网,仅用于学习及参考使用,切勿用于商业用途,如产生法律纠纷本站概不负责! 8、资源除标明原创外均来自网络转载,版权归原作者所有,若侵犯到您权益请联系我们删除,我们将及时处理! 9、若您需使用非免费的软件或服务,请购买正版授权并合法使用!
评论(0)